基础设施服务的微服务化
这篇文章是根据我在SFDC(SegmentFault Developer Conference)大会上的分享整理而成。

今天我给大家分享的题目是『基础设施服务的微服务化』。微服务这一两年非常火,今天的服务器端的分享主题应该至少90%和微服务相关。同时你会发现,云,容器等技术的发展都是在给微服务铺路,因为用户本质上需要的是服务,不是资源。但大多数和微服务相关的讨论都是分析业务应用如何微服务化,如何远程调用,如何服务治理,谈论基础设施服务的却很少,我们今天来聊聊这个。

讨论微服务,遇到的第一个问题就是多微的服务才能叫微服务呢?是否有个标准,比如多少行代码,多少个方法,多少个接口?
我们来看看微服务这个概念的最早定义:

我们不用全部仔细看完,只需看看我标出来的几个关键词:
- small service 这个好理解,就是微服务就是小服务。
- independently deployable 可独立部署。微服务就是将原来的共享库的依赖方式,改为远程调用的依赖方式,每个微服务都是独立部署的服务。
- fully automated deployment 完全的自动化部署。这点往往被大家忽略,为什么微服务就要完全的自动化部署呢?因为以前的几个服务,被拆分为成百上千的服务,如果没有完全的自动化部署,基本上是不可维护的。当然,你可以说『我就是不差钱,我就招上千个人来管这些服务』:)就不叫微服务了?也能行,但这也违背了我们搞微服务的目标吧。

所以我们再回归到微服务这个概念。我个人认为微服务化本身包含两层意思,一层是拆,这个大家提到的多,将大的服务拆成小的服务粒度,通过远程调用解决依赖。但同时它也有另外一层意思,就是合,就是整个系统的微服务的所有组件之间应该是一个整体的分布式系统,按集群化的方式来设计,服务之间能互相感知,进行自动化协作。
我们来看一个微服务的一个例子。
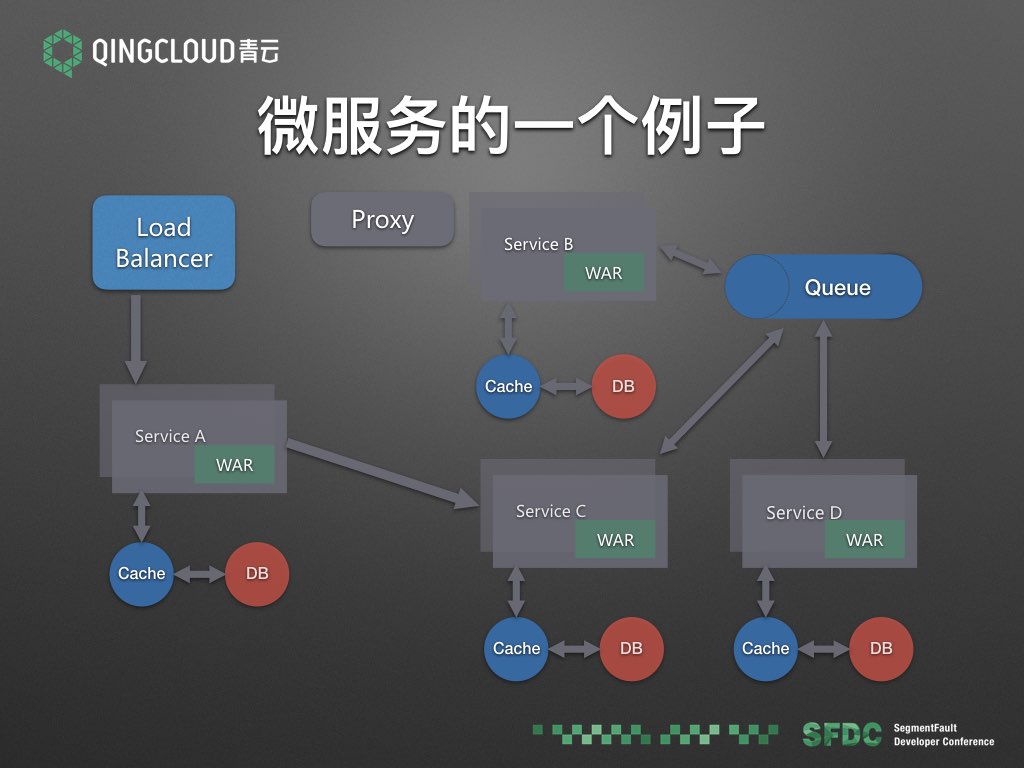
这里面有ABCD四个服务,每个服务都依赖数据库以及缓存,对外的服务有负载均衡器,服务之间互相依赖,异步交互通过队列进行。通过这样一个简单的微服务例子,我们可以看出基础设施都有哪些。

那我们的问题就来了 — 基础设施服务是否需要微服务化?

要解答这个问题,我们先看看当前的基础设施服务的主要解决方案:

第一种是大的互联网公司普遍使用的一种方案。基础设施服务托管给基础设施部门,基础设施部门包含运维,DBA 等。比如开发人员需要一套 mysql 服务的时候,提出申请,基础设施部门负责搭建和运维,开发人员只需要连接 mysql 的 IP 进行使用即可。另外一种方式是托管给云厂商,是使用当前云的基础设施服务。比如QingCloud,AWS,还有阿里云等,都提供基础设施服务,比如需要一套 mysql,在控制台即可创建,然后获取到连接 IP ,这样可以省去运维基础设施服务的成本。
但是这两种方式都有一些问题:

- 开发测试流程中的基础设施服务如何部署,如何自动化?这个没法委托给基础设施部门,需要开发人员自己动手搞。但开发人员一方面也没有精力搞一套完整的自动化工具,但即便是搞了,也解决不了开发环境和线上环境异构的问题。前面有位讲师的分享也说到了这个问题,异构问题总会导致故障,没出现故障也是时候没到。
- 另外一个问题就是基础设施服务迁移、伸缩、故障恢复时应用如何感知?比如有个 mysql 集群,当前数据库请求量太大,扩容了从库,应用如何自动感知到这个变化,从而使用新的从库?
我们再回顾下微服务的要求:

当前的基础设施服务的解决方案,不能满足微服务的集群化,自动化这两点要求。我们可以得出结论:

基础设施服务属于微服务系统中的一部分,需要和业务服务互相感知,需要被微服务化。
这就引出了我们的另外一个问题:

基础设施服务如何微服务化?这个主要有以下难点:

基础设施服务种类多样。比如前面那个简单的微服务系统,就用到了很多基础设施服务,各种服务的有各种不同的配置方式。同时,这些服务的集群机制也是多种多样的。我们举几个例子来说明下。

Zookeeper 的主要配置文件是 zoo.cfg,这个配置文件中需要列出整个集群中的所有节点,以及对应的server id。另外,每个节点还有一个独立的 myid 配置文件,这个文件中写了当前节点的 server id。比如要把这个集群扩展到5个节点,首先要要算出新的节点的 server id 号,生成新的节点的myid 配置文件,同时需要变更每个节点的 zoo.cfg 配置文件,把新节点的 server id 和 IP 都写进去,然后重启服务。

HAproxy 的配置文件中的每个 backend 后会配置一个 server 列表。如果后端服务伸缩,就需要变更这个 server 列表。

Redis Cluster 的这个例子我只是想说明下, redis 并不是通过配置文件来维护集群信息的,而是通过动态命令。创建集群,增删节点,都需要调用命令进行。
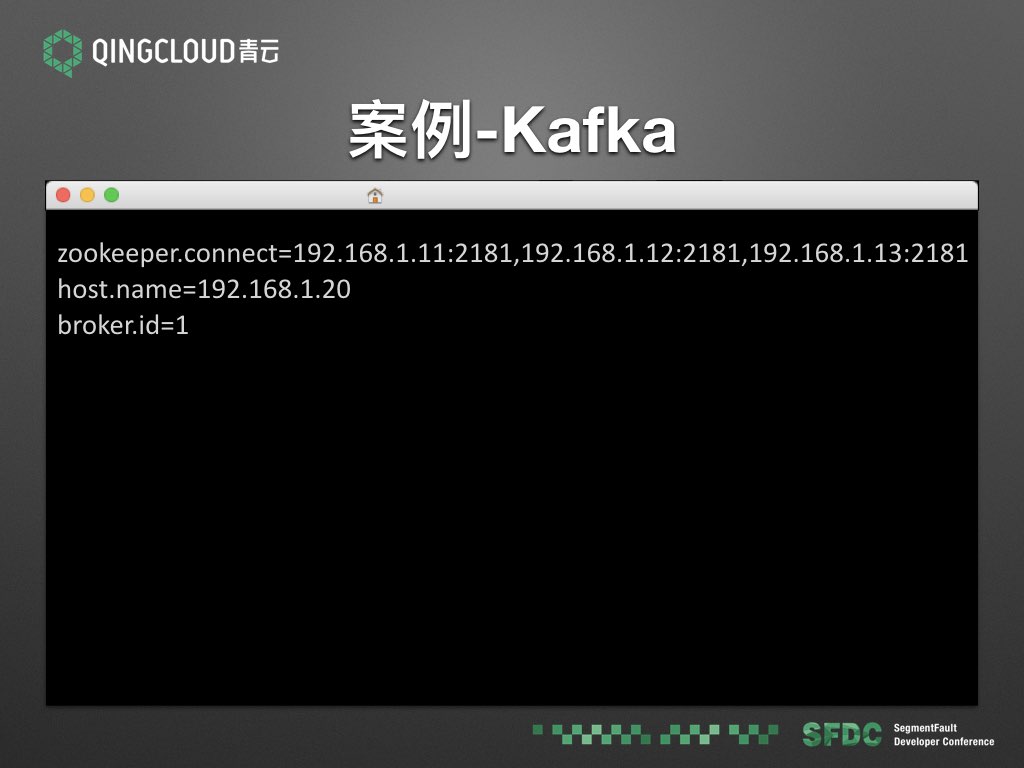
Kafka 是通过 Zookeeper 来做服务发现的,所以如果 Zookeeper 集群变更,就需要变更它的配置文件中的 zookeeper.connect 配置项。

粗略的看了以上的几个例子,大家对基础设施服务的配置和集群的多样性有了初步的体验。既然要微服务化,就需要设计服务的注册发现以及配置变更方案。微服务理想中的方案是应用内部自发现,监听配置中心,自动进配置变更。但现实的状况我们前面的例子也看到了,我们也不可能等待这么多的服务逐渐都改造升级了再用,所以唯一可行的办法就是通过非侵入的方式,进行第三方的服务注册,以及配置变更。
下面我介绍一下我们 QingCloud 应用调度系统的一些实践。
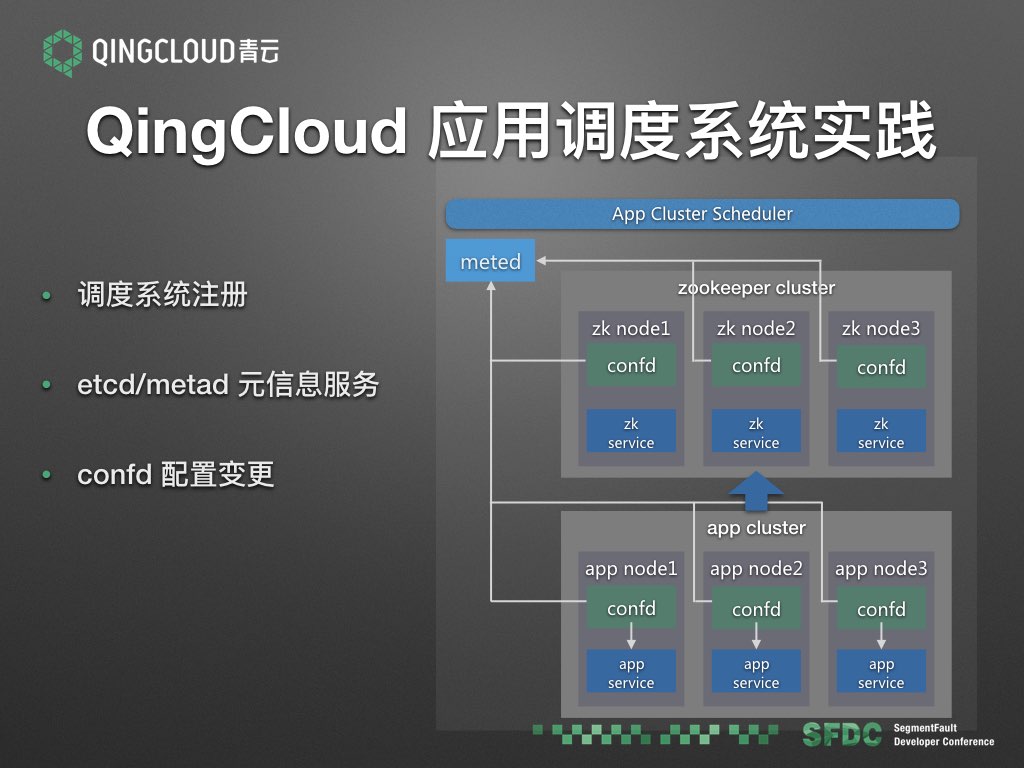
我们在 IaaS 调度系统之上构建了应用集群的调度系统,它知道集群里的 vm 节点的变化,然后将集群的基础信息注册到我们的元信息服务 metad 中。每个 vm 节点里面都运行一个 confd 进程,监听 metad 的元信息,一旦发生变化,则变更本地的配置和服务。比如左图的这个例子,应用集群依赖一个 zookeeper 集群,二者都关联在 metad 中。如果 zookeeper 集群的节点发生变化,应用集群是可以通过 metad 感知到变化,并且通过 confd 进行配置变更。下面我分别简单介绍一下使用到的一些组件。

Etcd 是一个开源的分布式的一致性 kv 存储,提供元信息的持久化,同时它支持 watch 机制,可以实现变更推送。

Metad 是我们自己研发的一个开源的元信息服务。它的后端对接 etcd ,和 etcd 实时同步数据。我们前面也说了,当前我们的方案是通过调度系统进行服务注册。这种注册方式有一个问题就是,节点启动的时候,它不清楚自己所处的角色,也就是不知道『我是谁』。人生哲学的头一个难题就是回答『我是谁』,服务器也有这个困境。所以我们在 metad 中保存了 IP 到元信息之间的映射关系,客户端请求一个固定的接口 /self 就可以拿到自己本节点的信息,当前节点所处的集群的信息,以及当前集群依赖的其他集群的信息。它也支持 watch 机制,实现变更推送。

Confd 是一个开源的配置变更工具,我们在其基础上进行了二次开发,后端对接 metad。它通过监听 metad 的变更通知,同步元信息到本地缓存,然后根据模板渲染配置文件,如果发现配置不一样,则进行应用的配置变更,同时触发脚本让应用程序重新加载配置(reload 或者 restart)。下面我们通过一个例子来说明下。
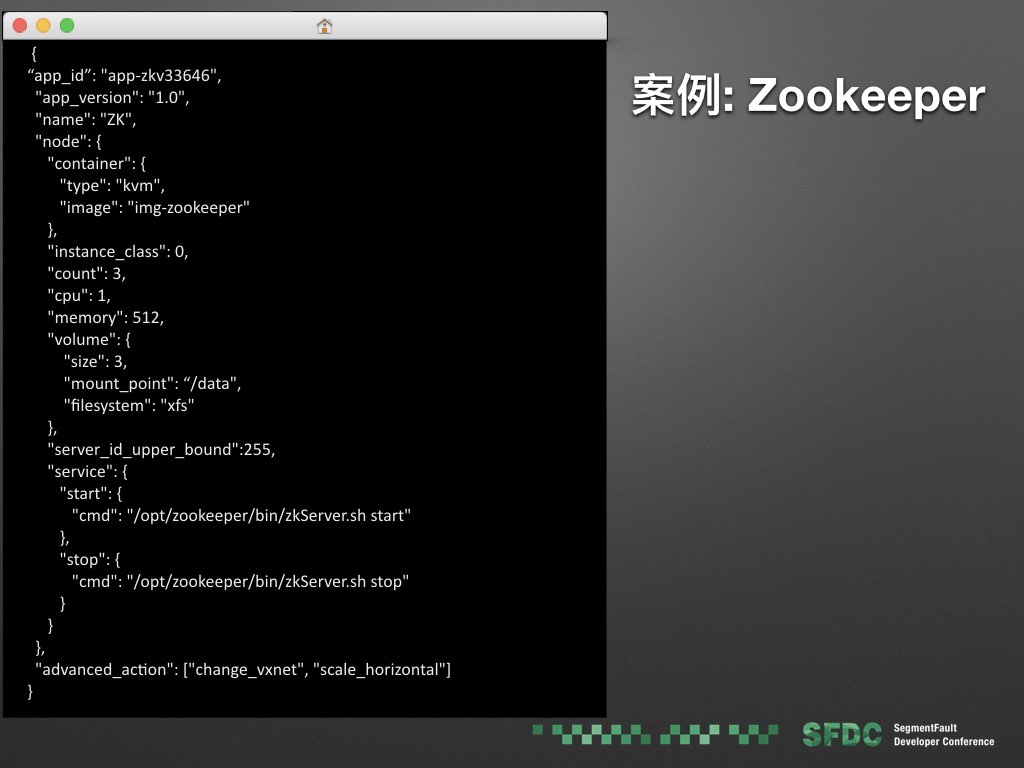
还是一个 zookeeper 的例子,我们首先有个集群的编排配置文件,定义了其中每个节点的镜像,cpu,内存,磁盘,节点数量,以及启动,停止等 service 脚本。

我们给 zoo.cfg 定义了一个配置文件模板,这个模板是给 confd 用来渲染配置文件的。模板的语法是 go template 语法,如果不熟悉这个模板语法也没关系,大家可以看出这段脚本是在循环配置中心的 hosts 列表,然后生成 server id 和 IP 之间的映射配置。

这是那个 myid 配置文件的模板,这个很简单,我们给集群的每个几点都会分配一个 sid,这种情况,直接吧 sid 写到 myid 配置文件就好。

同时,我们的集群编排支持 kvm 和 docker 两种镜像,这样就可以实现 kvm 和 docker 的混排。如果应用有特殊需求 docker 镜像不能满足,比如 kernel 版本,则可以使用 kvm 镜像。当然我们这里的 docker 镜像不是标准的 docker 镜像方式,镜像默认启动的进程,也就是 init 进程必须是 confd,然后应用通过 confd 来启动。这个方式和 大家用 docker 的习惯不一样,比如 zookeeper 的镜像,习惯启动的第一个进程就是 zookeeper 服务。
那我们为什么不用 docker 默认的方式呢?

这也是一个理想和现实妥协的方案。理想中的 docker 应用配置,应该是静态配置通过环境变量,动态的通过配置中心。比如 jvm 的启动内存设置就是静态配置,通过环境变量传递,如果应用需要变更内存设置,直接销毁旧的容器实例,重新启动新的并传递新的环境变量即可。但现实的状况,我们前面也举了好几个例子,大多数应用的配置还都是通过配置文件,无论动态还是静态。我们为了变更应用的配置文件,就需要通过 confd,所以我们的 docker 镜像默认先启动 confd。
以上就是我们当前的实践方案。下面我们和业界的其他一些方案做一些比较。

Ansible/Puppet/Salt/Chef 这一系列配置变更以及自动化工具,本质上都是纯静态的配置变更工具。它们是把变量通过模板渲染成配置文件,这里的静态指的是这些变量在编写配置规则时就是确定的,所以它们的复用机制不够通用。比如有人写了一个自动部署 zookeeper 集群的 ansible 模块,但当你想用这个模块部署自己的服务的时候,会发现需要有许多变量需要修改,比如网络,等等。它们的静态模式导致的另外一个问题就是服务的依赖变更不好解决,比如前面 HAProxy 那个例子,当后端服务伸缩的时候,要变更 HAProxy 配置,还是得手动修改变量,然后重新执行配置变更脚本。所以它们只能是半人工半自动化工具,对动态的故障迁移以及伸缩,容灾也没有好的办法。

Kubernetes 的目标是通用的容器编排系统,做了很多通用的抽象,试图通过 DNS,虚拟 IP 这样的通用机制来解决服务间的依赖问题。比如前面那个 mysql 的例子,mysql 从库伸缩后应用如何感知?它的解决方案是 mysql slave 可以作为一个独立的服务,会分配一个 DNS name,以及一个 虚拟 IP。应用连接的时候通过 DNS 以及虚拟 IP 进行,并不需要知道后面的每个从库节点 IP。但这种方式的问题就是有些场景满足不了,比如前面的 zookeeper,集群中的每个节点都需要能和其他节点直接通信,类似的还有 elasticsearch。Kubernetes 的 elasticsearch 解决方案是给 elasticsearch 写一个插件,通过 kubernetes 提供的注册中心的接口来发现集群中的其他节点。但如果应用不支持插件就比较麻烦,比如 redis cluster,文末有个 redis cluster 运行在 k8s 上的案例,做法是把每个节点都作为一个 service,如果要扩展节点的话,必须新增 k8s 的 service 配置文件,然后节点运行之后再通过手动调用命令进行初始化。它支持全局的配置文件映射,但只是纯静态配置,不支持变更。

Mesos 的目标是通用的资源调度和分配系统,如果把应用要放到 Mesos 之上,应用需要通过扩展 framework 来实现,开发成本比较高。如果用通用的容器方式,也有和k8s类似的问题。
所以当前看来,我们的方案是相对可行度比较高,容易实践,对各种不同的集群应用的包容性也比较高的方案。
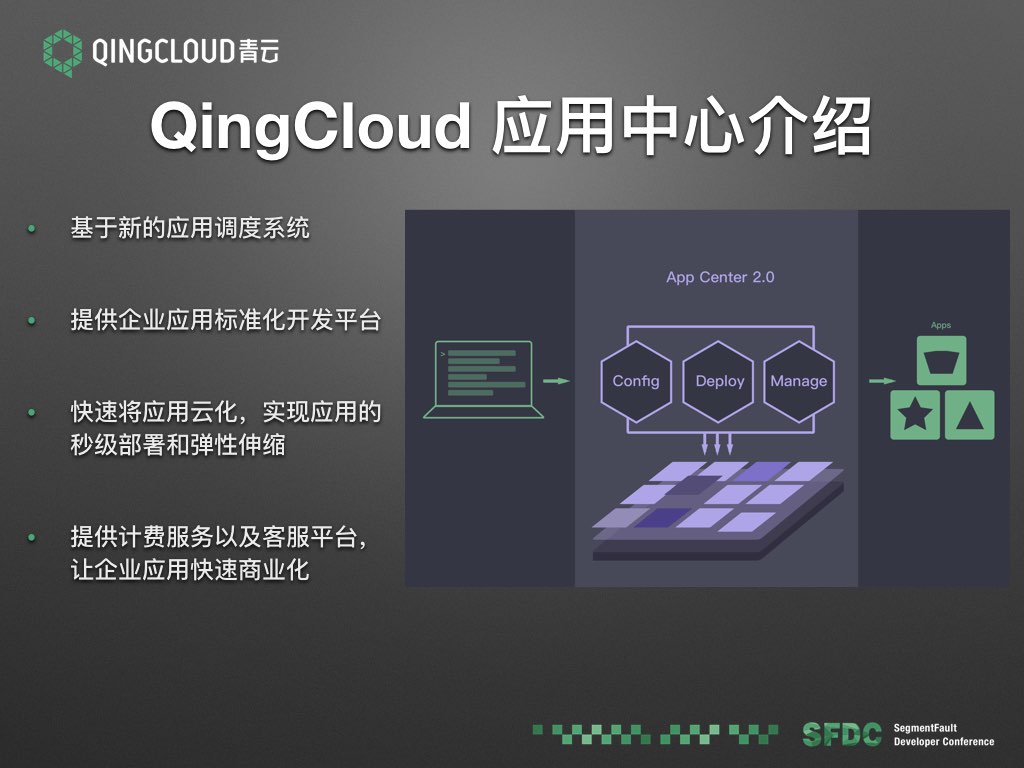
最后再介绍一下我们的新应用中心。主要基于前面的应用调度系统,给企业提供应用标准化开发平台,可以快速将应用云化,实现应用的秒级部署和弹性伸缩。同时提供计费服务以及客服平台,让企业应用快速实现商业化。当前还在邀请内测阶段。

那这个对我们开发者有什么意义呢?一方面我觉得可能会带来基础研发运维部门在企业中的角色转换。因为当前基础研发运维部门在企业中属于业务支撑的部门,基本上是成本部门,并不是直接生产利润的部门。但如果有了这样的平台,基础研发运维部门可以通过企业应用市场将自己的基础组件共享出来,进行售卖。比如每个大一点的互联网公司都会搞一套 mysql 的分布式的集群方案,进行自动的分库分表,如果能在应用市场中找到这样的工具,中小企业肯定也是愿意买单的。所以也可以说服务器端研发人员的春天到了。以前我们很羡慕搞客户端开发的人,自己做个 app 就可以放到应用市场去售卖,现在服务器端开发也可以了。我这里不是说我们一家就能把这个春天带来,而是说服务器端的应用标准化,已经是大势所趋,大家都在做这方面的尝试。可以做个预测,2017年,各容器编排集群,各云厂商,都会推出自己的类似的解决方案,可以期待。
我的分享就这里。
相关链接
- Etcd 架构与实现解析 本人的一篇关于 etcd 的文章,想深入了解 etcd 的可以看看。
- Kubernetes 架构浅析 本人的一篇关于 k8s 的文章,想深入了解 k8s 的可以看看。
- Mesos 架构以及源码浅析 本人的一篇关于 mesos 的文章,想深入了解 mesos 的可以看看。
- kubernetes cloud plugin for elasticsearch 文中提到的通过k8s api 进行节点发现的 elasticsearch 插件
- kubernetes 上运行 redis cluster 的例子
- confd 我们修改版的confd仓库地址。
- metad 仓库地址。