
Post
Based Booster Rollup 的背景、实践和展望
从 L1/L2 关系和应用构建角度,重新看 Based Booster Rollup 的背景、实践与边界。
Based Booster Rollup 的思路最近讨论很多,大多数是从安全角度来讲。我更关心的是 L1 与 L2 的关系,以及应用到底该怎么构建。所以这篇把背景、实践和展望放在一起说清楚。
Based Rollup 的思路其实很简单:用户直接把 L2 交易提交到 L1,由 L1 排序打包,但 L1 不校验交易有效性,只保证顺序和可用性,而 L2 是一个纯粹的执行器,负责执行这些已经打包在 L1 上的 L2 交易。看到这里其实就会觉得很眼熟:这和铭文(Inscription)模式很像。铭文的 Indexer 在某种意义上就可以理解成这里的 L2。
Booster Rollup 则从另一个角度出发:L2 如何通过合约直接读取到 L1 状态?思路也不复杂。既然 Based Rollup 已经在执行 L1 上的 L2 交易,那要不要顺便把 L1 的交易也执行一下?这样 L1 和 L2 的状态就在一个更大的状态树里,L2 合约就能直接读取 L1 状态了。
于是也有项目把 Based Rollup 和 Booster Rollup 合在一起,叫 Based Booster Rollup(BBR),比如 Taiko。
BBR 的背景
BBR 从提出到受到关注,核心背景是当前 Ethereum 主流 L2 方案带来的割裂问题:L1 与 L2 的割裂,以及 L2 之间的割裂。现在很多 L2,从开发者和用户角度看,和一条 Alt-L1 已经没有太大差异。读取 L1 数据要依赖 Oracle,资产还得过桥,钱包也得切换网络。而这种割裂还带来另一个问题:L1 和 L2 的绑定并没有那么紧密,L2 随时可以增加一套共识机制,把自己演化成一条 Alt-L1,并且让开发者和用户基本无感。
当前主要的绑定关系其实更多来自 EF 对正统性的约束:
- L2 必须把 L1 作为 DA。
但这个约束本身并不牢靠。
那如果把现在主流的 L2 都换成 Based Rollup,问题是不是就解决了?其实不能。Arbitrum 和 Optimism 现在即便都能通过 Force Inclusion 让用户直接向 L1 发交易,但它们还是割裂的,因为它们各自只认自己的交易。要想真正解决割裂,关键不是“交易是不是直接上 L1”,而是多个 L2 之间有没有可共享的数据格式和协议层。
这个共享数据格式至少要满足两个要求:
- 它必须与平台和实现无关,是在 L1 上定义的公开格式。不同 L2 的账户模型和虚拟机不一样,各自的专用交易没法直接共享。
- 它需要在多个 L2 之间达成共识,被多个 L2 同时支持。
所以它必须是协议先行:先设计公开协议和数据格式,链上只保存协议必须的数据,执行和校验在链下,不同 L2 各自实现支持方案。但这件事其实很难。Ethereum 生态更习惯通过智能合约定义协议,而不是先从数据格式开始设计协议。这个方向比较接近的尝试,反而是铭文热潮期间出现的 Ethscriptions。
从 BBR 到 Stackable L2
如果所有交易都直接由用户发给 L1,体验就会回到使用 L1 本身,无论是 Gas 还是确认时间。于是有人开始设计 Based Rollup 的预确认协议。但如果预确认协议真的要工作,并且所有交易都必须先经过预确认协议,那本质上它又变回 Sequencer 了。
这里的关键是不要把几类交易混在一起:
- 用户直接提交到 L1,并由 L1 执行和验证的交易,也就是 L1 交易。
- 用户直接提交到 L1,但 L1 不直接验证和执行,而是作为多个 L2 共享协议的数据交易,可以理解成 L1.5 交易。
- 用户直接提交给某个 L2 的 Sequencer,由 Sequencer 预确认并执行的交易,这是某个 L2 的专用交易。
Based Rollup 主要和前两类相关,而第三类其实仍然可以和它结合。假如有这样一个 Rollup:
- Sequencer 自动同步所有的 L1(包括 L1.5)交易,并严格按 L1 给定顺序执行。
- Sequencer 同时接收 L2 交易,和 L1 交易混排、执行。
通过第一点,它实现了 Based 和 Booster;通过第二点,它又保留了 L2 交易的快速确认,不损失用户体验。
这就是我更愿意叫做 Stackable L2 的东西:在 L1 上再堆叠一层 L2,L2 包含了 L1 的所有交易和状态。
Bitcoin 生态里的实践
这个思路如果放到 Bitcoin 上,反而会更自然一些。因为 Bitcoin 本来就没有图灵完备的智能合约,Based Rollup 模式下这一点不是劣势,反而逼迫生态更早开始围绕数据协议来设计系统。无论是染色币、RGB、Taproot Assets、Ordinals、Atomicals 还是 Runes,本质上都属于这条思路下的尝试。
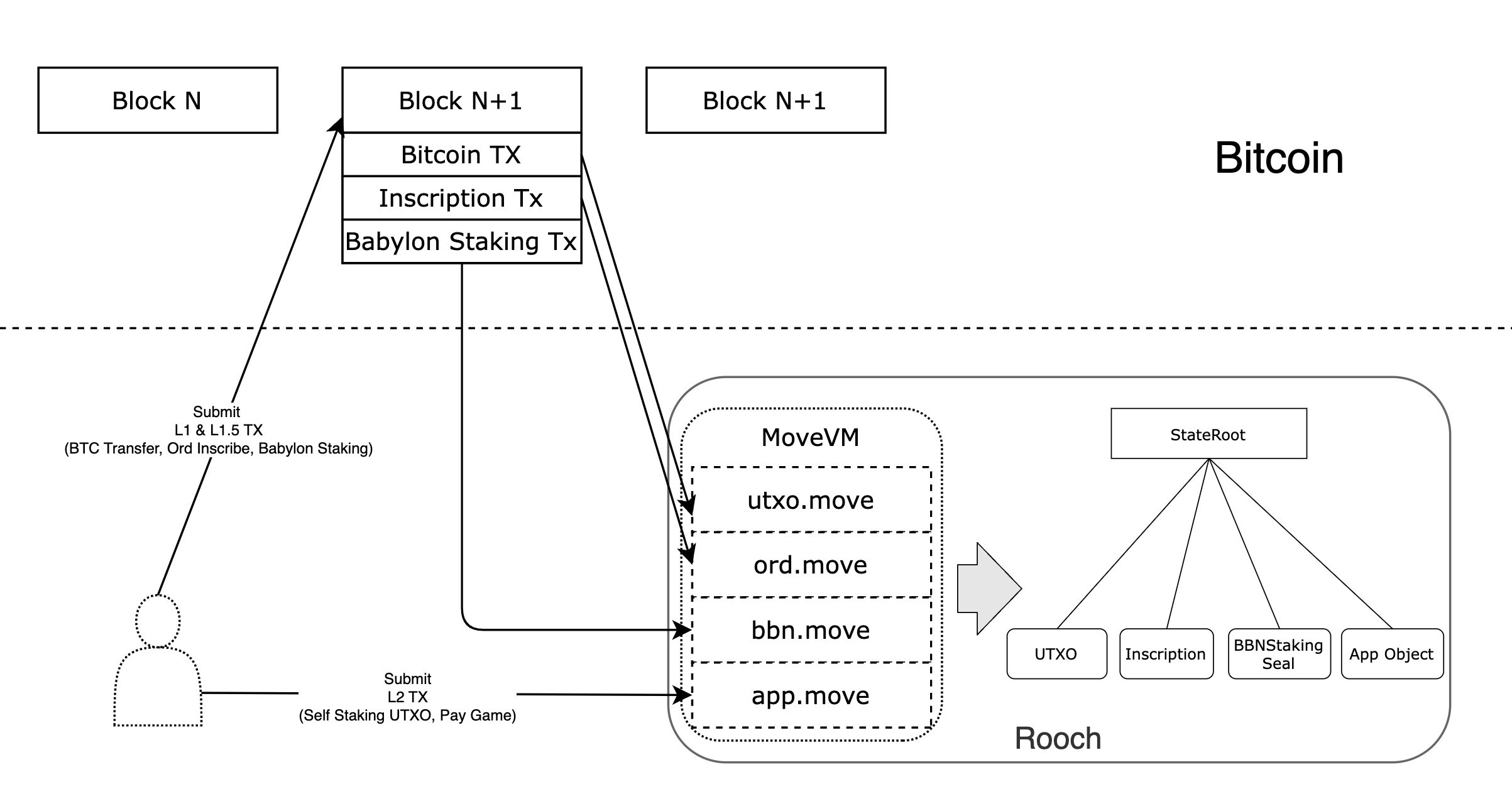
以 Rooch 为例,可以这样理解它的工作模式:
- 用户直接把 L1 和 L1.5 交易提交给 Bitcoin,入口可以是任何应用。
- Rooch 同步所有 Bitcoin L1 交易,处理其中的 UTXO,同时识别其中是否携带了额外的协议数据,然后由对应的 Move 模块处理。比如识别为 Inscription 的交易交给 ord 模块处理,而 Babylon Staking 的交易交给 bbn 模块处理。
- 用户再把 L2 交易直接提交给 Rooch 的 Sequencer。这样三类交易共同执行,最终生成一个完整状态树,应用合约可以同时利用 L1、L1.5 和 L2 的状态。
这种模式下,应用可以同时设计两种交易:
- 公共协议交易(Based 部分,在 L1 上)
- 应用专用交易(由 Sequencer 排序)
二者通过 Booster 模式互相配合,既保证 Permissionless,也尽量不牺牲用户体验。
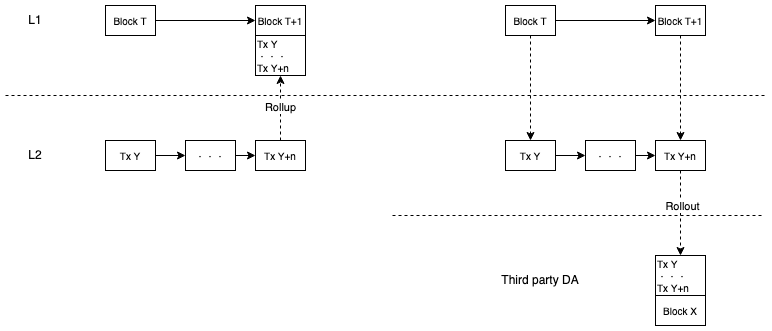
Rollup 还是 Rollout
如果采用上面的方案,L2 再把自己的交易打包提交到 L1,会有点奇怪:L2 会再次把“打包自己交易的那笔 L1 交易”读回来重新执行,自己的输出又变成自己的输入。所以 Rooch 更倾向于 Rollout 而不是 Rollup。
原因也很直接:L1 的区块空间很珍贵,多个 L2 都去争抢 L1 空间,是一种“内卷”。L1 的空间更适合留给 L1 和 L1.5 交易,L2 应用级交易应该去寻找更低廉的区块空间,通过“外卷”来扩展新的区块空间。
这个方向的价值
从 DeFi Summer 之后,整个 Crypto 行业一直在探索 DeFi 之外的新应用。无论是 Bitcoin 铭文热潮,还是这波 Based Rollup 讨论,本质上都可以理解成对 L1 作为公共数据总线(Data Bus)价值的重新发现。
从分布式系统角度看,通过数据总线可以实现系统之间的解耦,而系统之间的解耦是实现 Permissionless 的关键前提之一。Crypto 生态里的去中心化交易所,其实就是充分利用了区块链这个 Data Bus,实现了一种去中心化的系统对接。如果未来想支持更复杂的应用,只需要把简单的转账交易升级成应用协议交易,就可能实现应用层面的 Permissionless,而这种方式对现有应用的侵入性最小。