
Post
持续集成系统的演进之路-实践篇
把持续集成真正落到团队协作、Docker 和多环境部署时,会遇到哪些具体问题。
本文是持续集成系统的演进之路的实践篇,是本人在dockone群组分享内容的整理。
我们是一个初创团队,Grouk我们研发的团队通讯工具。我们的docker使用经验还比较浅,来这里和大家探讨学习。
我在一篇持续集成的演进之路中分析了持续集成的几个进阶:
- 代码级别的集成
- 集成workflow
- 持续部署与交付
- 并行多workflow集成以及个性化集成
这次分享相当于是这篇文章的实践篇。
代码级别的集成就是只做单元测试,和代码检查。这阶是用不到docker的。到第二阶,要做workflow了,需要部署环境,才需要docker。第三进阶,需要部署到生产环境,使用docker也会降低部署成本。最后第四进阶,每个分支都进行环境部署和集成测试。如果没有docker支持的话,实现成本就太高了。
我们的持续集成流程
我们使用的语言主要是java,build工具使用的是gradle,持续集成使用的是Teamcity。 下面是我们的持续集成workflow,是Teamcity的buildchain截图。

-
build 基本上是代码级别的编译,单元测试,代码检查
-
integration_test 单实例集成测试。
我们所有依赖的资源都有内存版的替代,这样我们可以将所有服务在单进程中启动进行集成测试。这样做有几个好处:一是减少集成测试的耗费的时间,这非常重要,持续集成就是要能做到快速反馈。二是方便统计集成测试的测试覆盖率。三是方便本地开发测试,直接可以在IDE中启动服务进行debug。
-
build_docker_image 打包docker镜像。
我们是将代码以及配置一起打包到镜像里的。开始我们打包镜像使用的是shell,后来我们该成gradle插件。主要原因是我们有5个模块要打包5个镜像。打包每个镜像需要5分钟多,5个就将近半个小时。改为gradle后,打包可以多线程并行,现在可以在10分钟内。
另外说下,gradle的docker插件gradle-docker有bug,我们做了一些改进,详细可以参看https://github.com/GroukLab/gradle-docker
gradle打包docker的配置例子:
docker { useApi true hostUrl "${docker_host}" baseImage "${base_image}" maintainer "xxx@email" registry "${docker_registry}" apiUsername 'username' apiPassword '' apiEmail 'xxxx@domain' } -
deploy_test_env 部署测试环境
我们当前还没用到复杂的docker集群编排工具,直接使用脚本+docker直接部署的。包含了mysql,redis,mongodb,elasticsearch,logstash以及自己的服务,一起部署,初始化。
测试环境每次进行集成测试都是重新初始化的。 -
test_env_integration 测试环境的集成测试
对测试环境的部署进行集成测试,测试用例和前面的单实例集成测试是一套的。
-
deploy_sandbox_env 部署沙箱环境
沙箱环境和测试环境基本是一样的,唯一区别是沙箱环境的数据是多次积累的,不会每次初始化。
-
sandbox_env_integration 沙箱环境的集成测试
-
deploy_production_env 部署生产环境
我们线上环境的服务也是用docker部署的,但资源服务使用的是云服务提供的,并没有部署到docker中。
-
production_env_integration 进行生产环境回归测试
-
clean-up 清理环境
持续集成最佳实践
持续集成的演进之路中列举了一些持续集成最佳实践,下面我摘几点介绍下我们的具体做法:
-
集成测试用例最好使用项目本身开发语言编写和单元测试类似,至少是团队开发人员都熟悉的语言。并且项目代码要和集成测试用例在同一个源码仓库里。
我们的集成测试是直接用java写的,放到单元测试的目录里。不同环境的集成测试通过环境变量进行控制。直接通过gradle的task调用进行集成测试。 下面是gradle的集成测试task例子:
task testTestEnv(type: Test) { systemProperty "ums.env", "test" } -
服务最好不依赖外部容器,可以独立运行
我们当前是内嵌netty和jetty,通过main方法直接运行服务,然后通过gradle的application插件生成启动脚本。这样的好处是应用可以直接启动,方便开发调试以及集成测试。java的容器是企业应用为了降低部署成本带来的习惯,但当前虚拟化,docker等技术这样成熟的情况下,应用容器已经完全没必要了。
这点上go,nodejs等新的语言做的比较好。java也可以用spring-boot。
-
最好提供一种直接可以单进程运行整个系统而不依赖外部资源的配置
我们是提供了一套专门用于dev环境的配置,mysql用h2这样的内存数据库替代,redis,mongodb用java版本的内嵌server,服务可以不依赖外部资源直接启动。这样的好处前面也说了,可以快速集成测试,以及统计集成测试覆盖率。
我们遇到的问题
-
镜像版本问题
teamcity的BuildChain是可以并行的,如果一直使用latest,会出现后面的部署操作把前面的尚未进行集成测试的镜像给部署了。所以我们改造了下,镜像是按照CI的build number设置版本号的,整个workflow的每一步共享一个版本号。源码的tag,java的jar包版本号,以及docker镜像的版本号都是可以对应的。 -
镜像更新频繁导致docker storage分区空间用完
因为每次更新大约要拉取100多M的增量变更,时间长了storage分区空间用完,docker deamon 挂掉。改进了部署脚本,最后增加了cleanup脚本。 -
部署脚本问题
虽然docker降低了部署成本,我们可以实现一键部署一整套环境,但由于大量依赖shell脚本,失败检测等机制做的也不完善。存在部署风险。 -
Pets和Cattle

这是云时代无论是虚拟机还是容器想要解决的问题。对待机器节点要像Cattle而不是Pets。
我们现在的方案还是把容器当做Pets,要关心容器到主机的端口映射,要关心网络的互通,本地磁盘的映射路径等等,部署,迁移,变更都比较复杂。
当前正在进行的改进
我们当前还没做到我说的持续集成的第四进阶,多分支并行的集成测试。
理想的CI流程测试如下图:
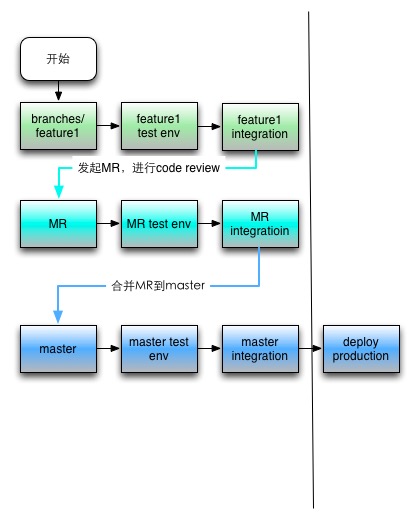
- 每个分支的提交也都需要进行集成测试
- 从分支发起MergeRequest(MR)后,CI在本地进行merge后进行集成测试,将测试结果汇报到MR页面。
- Code Review后,MR合并到master,重新进行整体的CI流程,直到自动化部署完成。
要做到这步的困难点有几个:
- 要能快速复制一整套环境,并进行初始化
- 要有服务发现以及负载均衡服务,给新的测试环境分配域名和负载均衡入口
我们开始想尝试直接通过脚本调用云服务提供的api做这个事情,但发现比较困难,虚拟机启动也比较变慢,遂放弃。 去年也尝试过搭建kubernetes(k8s),但发现还不太成熟,没太多精力尝试,也放弃。
前一段时间k8s的1.0发布,感觉应该相对比较成熟了,我们又开始尝试搭建k8s集群,想通过k8s来做这个事情。
我们在k8s上也遇到了难点:
- docker节点的网络互通 通讯服务和其他服务区别比较大的是节点之间需要直接连接进行转发消息。而k8s/docker容器直接网络互通这块的解决方案都还不是太成熟。
- 长时间运行的数据库服务在k8s中如何调度运维?数据迁移和HA如何实现?
- 依赖多种资源,多个服务模块,并且模块有依赖关系的应用如何整体定义?如何升级?
我们尝试k8s,其实不仅仅是想在持续集成中使用,还有个想法是给企业提供私有部署。
假设k8s可能会成为未来的云操作系统,企业的私有云上也部署的是k8s,这样我们提供基于k8s的部署,就可以实现一键部署到企业内网,降低了企业应用私有部署的部署运维成本。
这方面还得期望各位docker的大牛们和各云厂商给提供解决方案。
好了,我的分享结束。另外打个广告:我们的团队通讯应用正在公测,欢迎试用:Grouk
Q&A
Q1. CI过程中test需要连接数据库的代码时,您在写测试案例方面有哪些经验分享。
单元测试不能依赖外部资源,用mock,或者用h2等内存数据库替代。集成测试的时候是从接口层直接调用测试的,测试用例对数据库无感知。
Q2. 请问部署到生产环境是自动触发还是需要手动审批?sql执行或回滚是否自动化?
当前是需要手动触发。sql更新当前没做到自动化,这块正在改进,因为部署私有环境需要。sql不支持回滚,代码做兼容。docker镜像回滚没有自动化。
Q3. 问一下你们的redis内存版是用的什么?
我们用的内存版的redis是 https://github.com/spullara/redis-protocol 中的server实现。不过这个实现部分功能没支持,比如lua脚本,我们自己做了改进。
Q4. 介绍下workflow带来的好处
workflow的好处我那篇文章中有说明,如果没有workflow,所有的步骤都在同一个配置的不同step实现,如果后面的失败,要重新从头开始。workflow可以中途开始,并且每一步骤完成都会触发通知。
Q5. h2并不完全兼容mysql脚本,你们如何处理的?
我们通过一些hack的办法,会探测下数据库是什么类型的,替换掉一些不兼容的sql,进行容错。
Q6. 请问你们在构建的时候,你说有些需要半个小时左右,那么构建过程的进度监控和健康监控你们怎么做的呢,如果有build失败了怎么处理呢
ci的每一步都有进度的,并且我们的团队通讯工具可以和CI集成,如果失败会发消息到群里通知大家
Q7. 深圳Q3:cleanup脚本做哪些?
主要是清理旧的docker镜像,以及清理自动化测试产生的垃圾数据。
Q8. 请问你们文件存储怎么解决的呢?使用自己的网络文件系统还是云服务?
文件系统支持多种storage配置,可以是本地目录(便于测试),也可以使云服务(比如s3)
Q9. 刚才说你们能通过一键部署,但是中间无法监控,测试环境可以这么玩,那生产环境你们是怎么做的呢?还有你们后续的改造方向是自己开发?还是采用集成第三方软件?
生产环境shell当前只能是多加错误判断。这块我们在改进,比如通过ansible等工具,以及使用k8s内置的rolling-update。自动化部署这块还没有好的开源工具。
Q10. 你们的测试用了很多代替方案、如h2代mysql,要保证测试效果,除了你们用的hack方法之外,是不是从写代码的时候就开始做了方便测试的设计?
对。这也是我文章中分享的观点之一。测试用例的编写人员要有业务代码的修改权限,最好是同一个人。要做自动化测试,业务代码必须要给测试留各种钩子以及后门。
Q11. 请问你们的集群应用编排怎么做的?
上面说了,还没用到编排。一直等编排工具的成熟。正在测试k8s。
Q12. 你们做这个项目选型是出于什么考虑的,介绍里有提到使用一些脚本来管理容器解决开发和测试各种问题, 感觉这种管理容器方式过于简单会带来管理问题,为何不用第三方开源项目来做二次开发,如:Kubernetes;另一个问题是,下一步有没有考虑如何让你的docker和云服务平台结合,要解决运营成本问题(docker最大吸引力在这里),而不只是解决开发测试问题。
因为我们最早用的时候k8s 1.0 还没有,变化太大,创业团队没精力跟进,脚本是粗暴简单的办法。一直在等待各种基于docker的云解决方案呀,肯定考虑结合。
Q13. 对于dockerstorage分区用完问题,我想问一下,你们是使用docker官方提供的registry仓库吗,如何解决仓库单点问题,这机器要是故障了怎么办?
registry用的是官方的,后端存储是挂载到s3上的。没有s3, 推荐使用京东田琪团队开源的 https://github.com/jcloudpub/speedy ,实现了分布式存储。
Q14. 除了介绍的Java相关的CI方案,对于C/C++开发语言有没有推荐的CI方案
Teamcity/Jenkins等CI工具支持任何语言的。其实任何语言的CI都差不多,单元测试,集成测试。关键还在于依赖环境的准备以及集成测试用例的管理。
Q15. 我看到你们为了方便测试和调试会有独立的集合docker环境,这种环境和上线环境其实是有差别的,这样测试的结果能够代表线上环境吗?这种问题怎么看待
所以我们有多个流程。清理数据的测试环境,以及不清理环境的沙箱环境。但这也不能避免一部分线上环境的数据导致的bug。另外就是配合灰度上线机制。当前我们的灰度是通过代码中的开关实现的,使用这种方案的也很多,比如facebook的Gatekeeper。
Q16. 请问Grouk有涉及前端(nodejs方面的)并结合docker的CI/CD经历吗。可以分享下吗?
这我们也在尝试。当前js的测试主要还是基于https://github.com/ariya/phantomjs ,纯粹的js库比较方便测试,但如果牵扯到界面,就比较复杂些了。