Post
从 Graphene 到 Steem 再到 EOS
从源码演进看,EOS 并不是完全重写,它更像是在 Graphene 和 Steem 之上继续推进数据模型、合约支持和性能路径。
读了一遍 EOS 的源码之后,我一个比较直接的判断是:它并不是一套完全从零开始的新架构,而更像是一条从 Graphene 到 Steem 再到 EOS 的演进链。
最开始听说 EOS 用了 Graphene 引擎,但真正看代码后会发现,Steem 基本是在 Graphene 上继续改,而 EOS 又是在 Steem 上继续改。所以整体架构上,EOS 和 Steem 很像,插件体系也类似。
真正关键的变化主要有三类:
- 支持
WASM智能合约。 - 对性能路径做了更多优化。
- 为了成为通用
DApp链,把原来偏业务化的数据模型做了抽象。
Steem 的业务逻辑很多是直接写在链代码里的,比如创建账号、发文章、评论这些能力,本质上属于链内建的一部分。EOS 想走的是通用应用平台路线,所以它把这部分能力抽象成更通用的合约和数据模型。
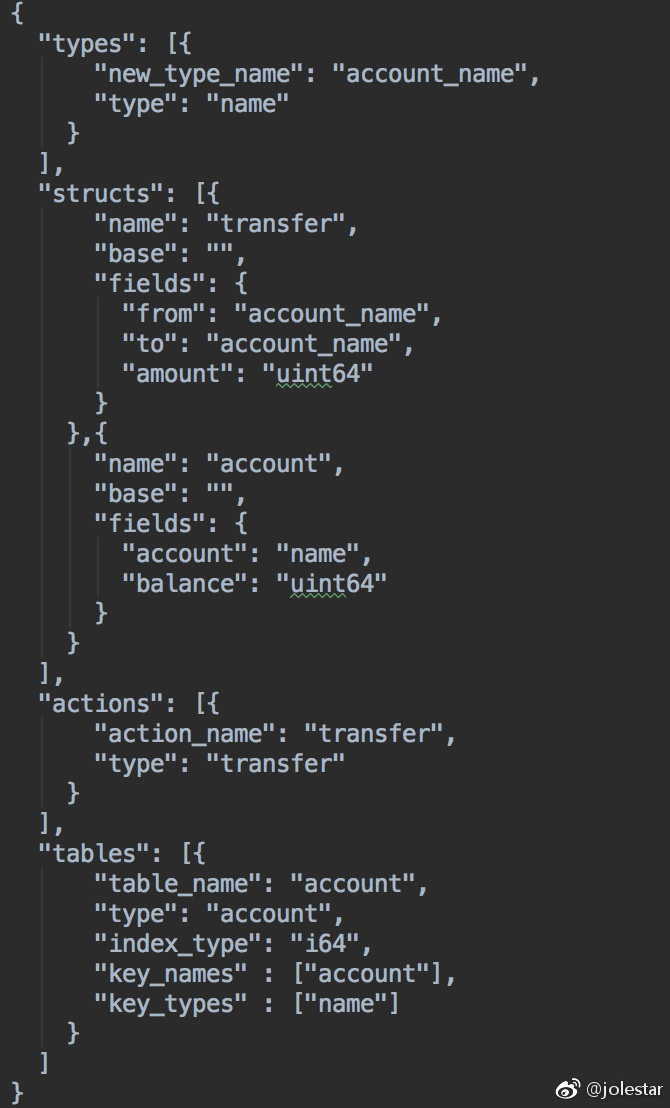
这点在它的 ABI 设计上体现得很明显。ABI 描述文件里会定义数据类型、字段、表结构和索引。EOS 支持主索引和二级索引,相当于把数据存储和查询能力接管了一部分,DApp 只需要在智能合约里围绕这些定义好的数据类型处理业务逻辑。
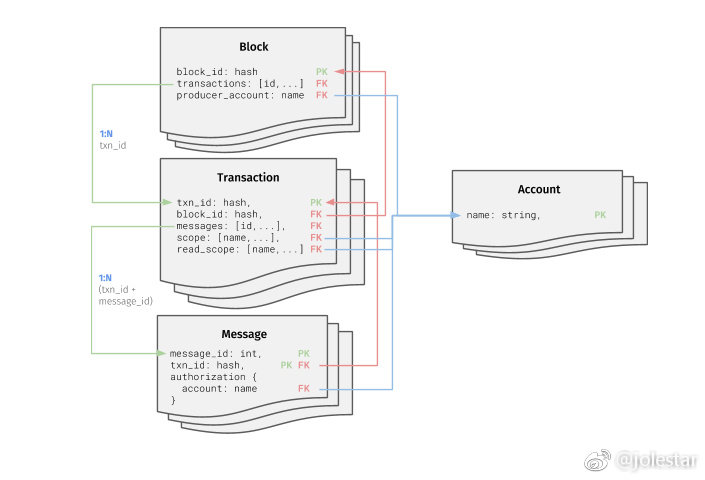
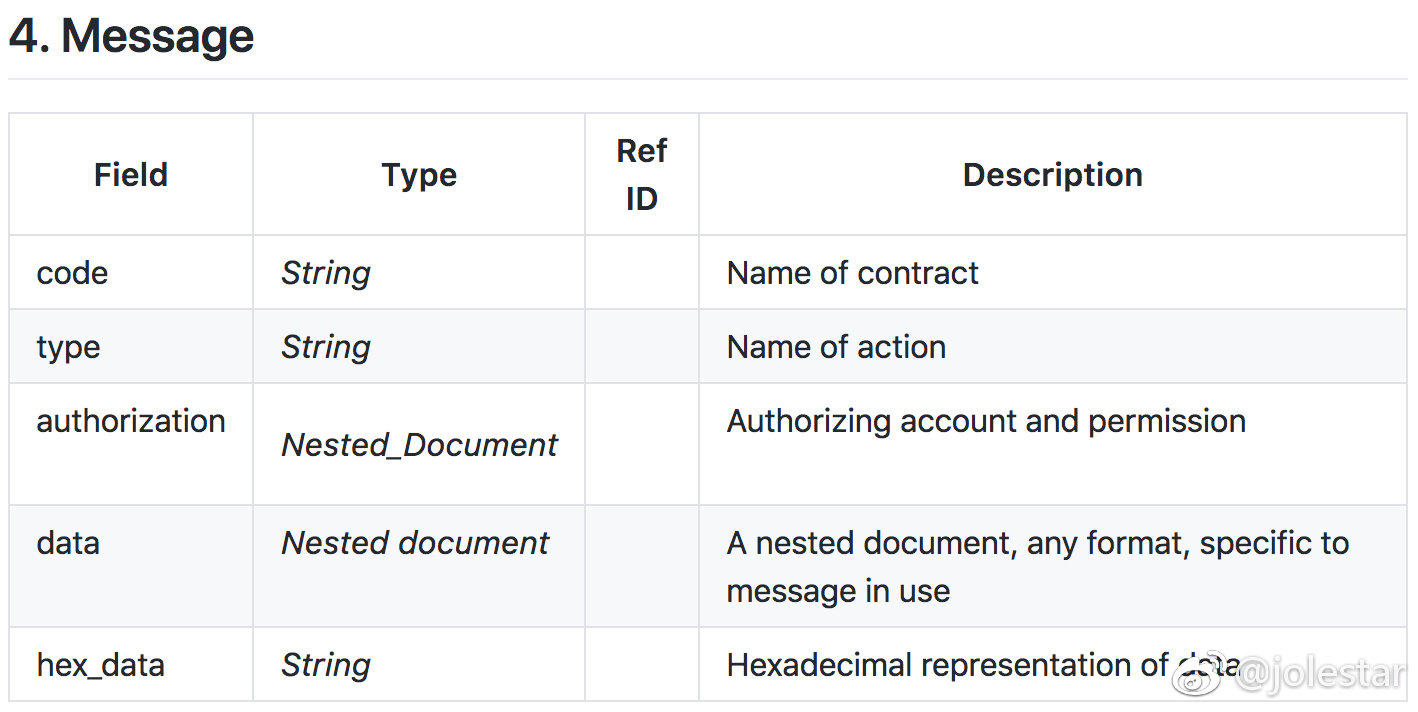
所以它的账本里记录的并不只是交易,而是 Message。Block、Transaction、Message 之间是另一种关系:Message 里真正描述的是合约里的 action 以及对应的数据对象。
比如如果要用 EOS 实现一个类似 Steem 的文章系统,你可以先定义一个 Article 数据结构,把字段、表结构索引、支持的 action 都写进 ABI 文件,然后在智能合约里通过 apply 方法按不同 action 做校验和业务处理。客户端只需要构造数据,再通过接口发送 Message 即可。
从这个角度看,EOS 在支持 DApp 上,确实比早期 Ethereum 更进一步一些。只是当时 WASM 可用语言还比较有限,主要还是 C/C++,其他语言支持还在补。
另一个我注意到的问题,是它对状态证明和存储的处理方式。EOS 的区块里只存 Merkle root,没有把整棵树存进去。这个点当时 Vitalik Buterin 和 Dan Larimer 还争论过:Vitalik 认为这有点取巧,Dan 认为 Merkle tree 的意义主要是为了校验状态,而状态本来就应该是链上记录回放出来的结果,不该成为共识里必须完整存下的一部分。
另外,EOS 和 Steem 都依赖 chainbase 这个数据库实现。它的思路比较激进:主要基于 memory mapped file,不太信任 LevelDB 这类数据库在性能和多级索引上的表现。它认为对区块链来说,状态数据库只是账本日志的一个快照,所以没必要按照传统持久化数据库的保守思路来设计。
所以整体看下来,我会觉得 EOS 的路径很清楚:通过 DPoS 超级节点机制把性能抬高一个量级,再加上更偏平台化的合约模型,去承载一些轻量级 DApp。这样跑一些应用肯定比早期 Ethereum 更从容,至少不至于像当年“跑个猫就堵链”。
但即便如此,我当时对公链直接承载大量上规模 DApp 这件事,还是没有那么乐观。
原微博中的媒体