Post
IPFS 和 IPLD 把内容与结构都变成了网络的一等公民
IPFS 让内容脱离托管商成为一等公民,IPLD 则进一步把结构化数据和可链接关系带进来。
最近抽空看了一下 IPFS 的近况以及代码,在内部做了一个简单的分享。它的设计其实很接近我对理想互联网的一种想象。原来我以为 IPFS 只能支持非结构化数据,所以总觉得差点意思;但看了 IPLD(Linked Data)之后,我反而觉得它比我原来设想的那条路还更先进一些。
先说 IPFS。
IPFS 的核心想法,是让内容本身成为互联网分发体系的一等公民,而不是继续依附在某个域名或托管商下面。今天互联网的内容,大多是“某个网站上的内容”,真正稳定的是平台,不是内容本身。而在 IPFS 里,内容的 ID(CID)直接由内容哈希来表示,用户关注的是内容本身,而不是内容托管在哪个商家那里。
比如一份博客内容,只要它的 hash 不变,那么无论你通过本地节点访问,还是通过 gateway 访问,本质上拿到的都是同一份内容。内容更新了,CID 就变,这当然会带来“难记”和“版本漂移”的问题,所以它又引入了类似名字系统的机制,比如 IPNS,来给内容绑定一个更稳定、更可记忆的名字。
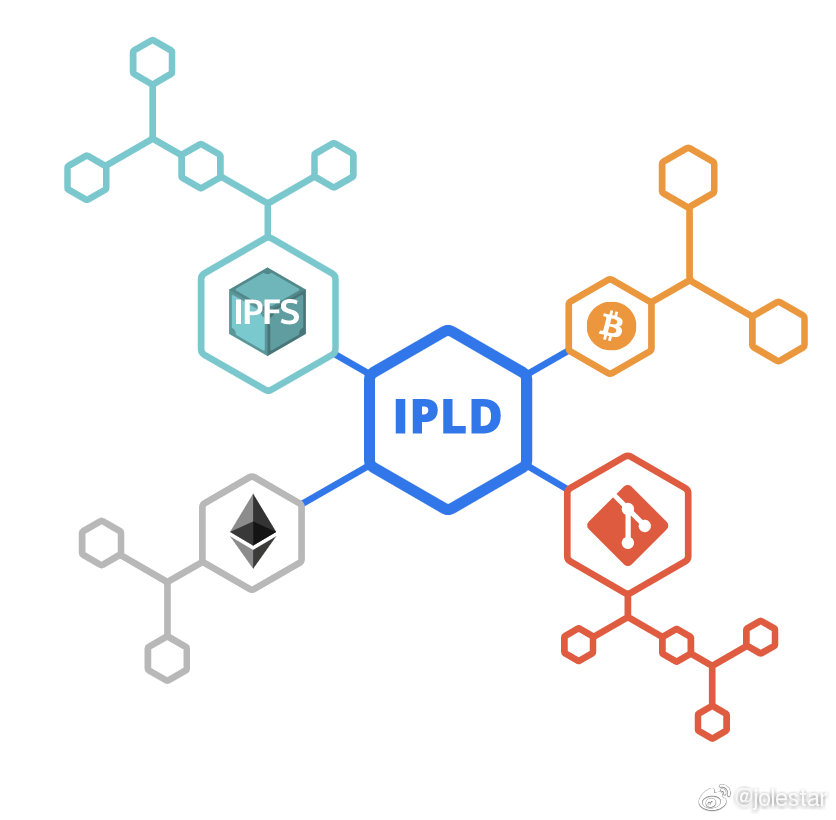
但 IPFS 真正让我改观的地方,是 IPLD。
如果继续拿博客举例:每次新增内容,根目录 hash 会变,但旧文章的 hash 不会变。可如果我只是换了网页模板,所有页面 hash 都可能变。那这个内容 ID 到底在标识什么?是最终渲染结果,还是那条真正的内容记录?
从最终用户视角看,用户真正关心的往往不是展示样式,而是内容本身。也就是说,内容 ID 更应该对应数据库里的那条记录,而不是某个 HTML 页面。这正是 IPLD 想解决的问题:如何把结构化数据保存到 IPFS 上,并且让数据之间能够天然链接。
IPLD 设计了一套数据格式规范。你可以把它理解成一个更通用的 JSON,但它里面允许出现 link 类型字段,用来表达“这条记录和另一条记录之间的关系”。而 IPFS 提供的,就是这类结构化数据的存储与寻址能力。
这样一来,整个网络就有点像一个被摊开的数据库。它没有库和表的中心入口,只有一条一条独立记录,通过 link 相互连接。你只要拿到某个 hash,就可以沿着链接继续把相关数据一层层找出来。
如果先不考虑性能和易用性,理论上这套机制可以承载很多应用。比如一个去中心化微博:每个人把内容发到自己本地节点上,关注某个人,本质上就是自己的节点和对方节点建立同步关系。
我甚至会期待有人把程序员依赖的那套资源体系都迁到 IPFS 上:比如 Linux 的 rpm/apt 仓库、编程语言依赖仓库、技术文档等等。用户本地起一个 IPFS 节点,常用数据自动同步过来,再配一个代理。安装或构建时,如果发现需要的数据已经在 IPFS 上,就直接从本地或附近节点获取,这对团队开发效率会是很直接的提升。
当然,IPFS 离成熟还差得远,比如缺身份体系、缺稳定的付费和激励机制。这也是为什么我会关注它和区块链的结合,比如 Filecoin 这种方向。我对这种结合最感兴趣的,反而不是存储激励本身,而是“读取数据也能被付费激励”这件事。因为一旦读取层也能形成稳定激励,内容供给和商业模式就会丰富很多。
从这个角度看,IPFS 的意义并不只是“分布式存储”,而是在尝试把内容、结构和链接关系一起从平台里解放出来。
原微博中的媒体