
Post
Web2 视角的 Web3
把 Web3 放回 Web2 产品和平台逻辑里重新解释。
前面写过两篇 thread,分别从 Web2 视角以及 AI 视角分析 Web3。这篇其实更偏工程实现:如果把 Web3 当成一种分布式应用基础设施,它和 Web2 的应用架构到底差在哪里?
在分布式应用中,我们一般会依赖 Paxos 或者 Raft 这样的分布式共识基础设施,来解决一些全局难题,比如元数据存储、全局锁、服务发现、事件订阅等。但我们并不会把所有数据都放进共识系统中。
如下图,是一个典型的 Web2 三层应用。用户发送请求,业务逻辑校验请求,然后修改状态并写入数据库。
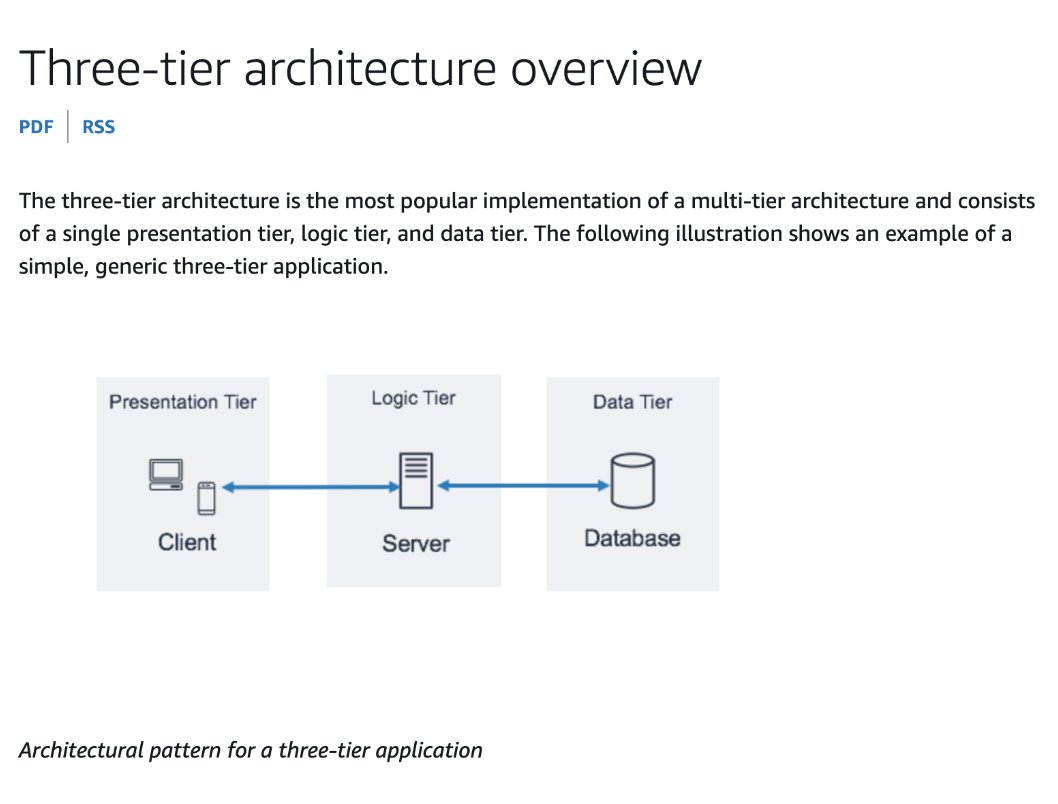
这个应用如果要实现分布式,第一步通常是把用户请求先记录到日志里,再通过一个全局的分布式日志系统同步到其他机房节点,然后在其他节点重新执行这个请求。这样系统才会逐步变成一个多机房的分布式应用。
当然,这只是一个简化模型。如果让一个大型 Web2 应用真正支持多机房,并没有这么简单。真实系统往往会混合多种分布式方案,复杂度远高于单一日志复制。
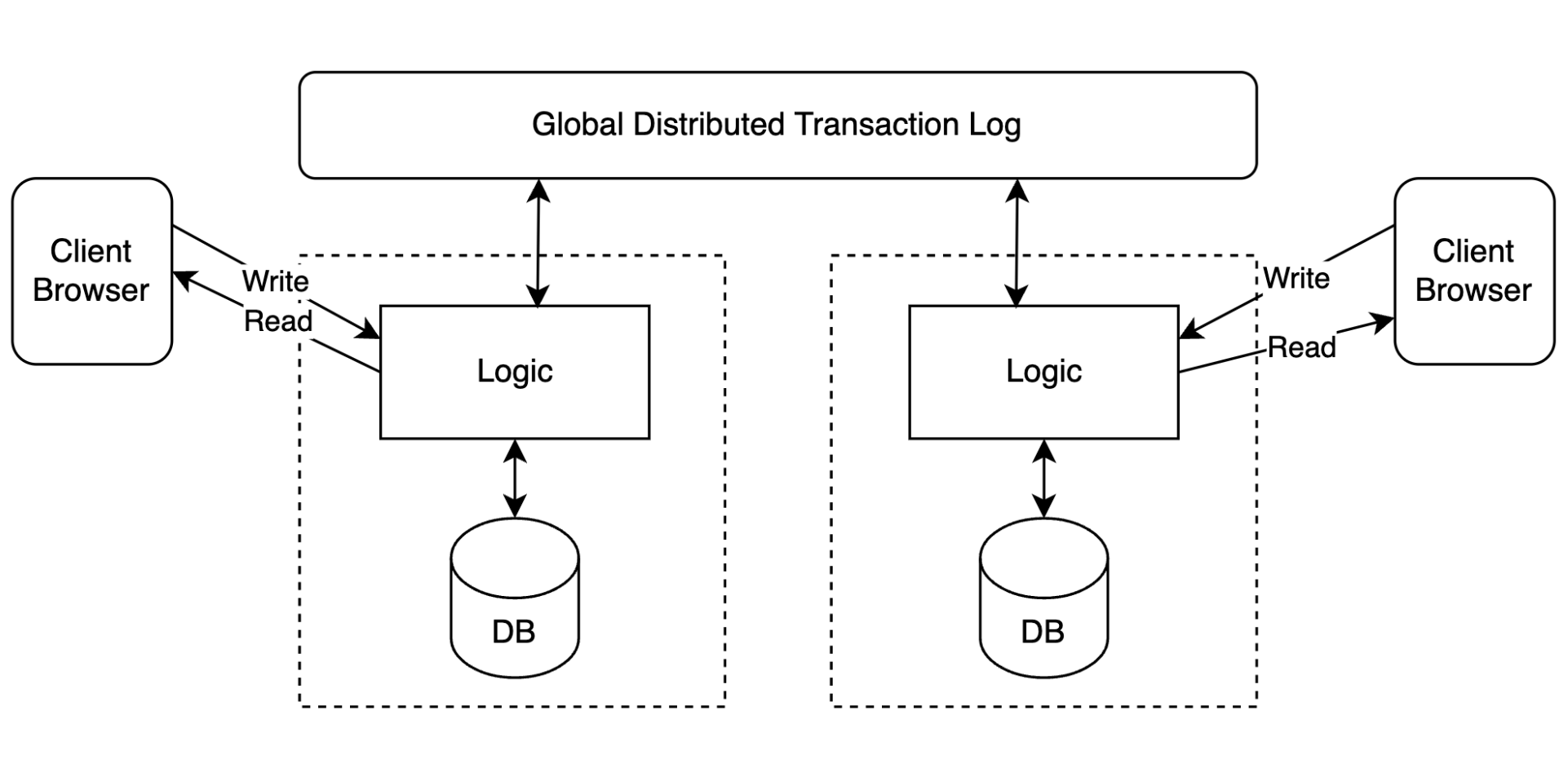
Web2 应用实现分布式的难点,本质上有两个:
- Web2 应用是围绕一个“活数据库”长出来的,很难通过一个统一入口记录所有状态修改。
- 即便拦截了全部状态操作,重新执行时也很难保证执行结果完全一致。
那如果从应用角度出发,如何利用已有的去中心化基础设施来解决应用的分布式以及去中心化难题?一个去中心化应用的潜台词,其实是它首先已经是一个分布式应用。
应用要去中心化,首先至少要保证两件事:
- 应用程序可公开获取。
- 应用数据可公开获取。
第一点可以通过开源实现,第二点则意味着:前面提到的全局分布式日志系统,需要换成一个公开的、不可篡改的去中心化日志系统。
这样任何人都可以通过重新执行账本中的交易日志得到最新状态。而这个去中心化日志系统,就是 Sequencer 和 DA 要解决的问题:它们一起保证交易顺序以及数据的公开可用。
但如果第三方重新执行交易,得到的结果和应用方不一样怎么办?那就需要一套机制来保证状态变化的正确性。这个可以通过欺诈证明的挑战机制,或者 ZK 的有效性证明来解决。而无论是哪种方式,都需要一个可以执行验证程序的可信第三方,这正好也是当前 Layer1 智能合约可以承担的职责。
如果顺着这个视角看,Web3 并不只是“加了 Token 的应用层”。它更像是:
- 用去中心化日志系统替代中心化协调系统;
- 用公开可验证的方式替代内部隐式状态;
- 用链上或链边的验证机制替代单点信任。
从这个角度看,很多 Web3 基础设施其实都可以理解为一种新的分布式系统基础设施,只是它的目标不是单纯追求性能或者一致性,而是在这些目标之外,再加入 Permissionless 和可验证性。