-
Avidemux简易教程
-
Null Object 模式之我见
写了个cache服务器的抽象层,如果cache中不存在该对象,我就让它返回null。
public Person fetch(String name){ //do some thing.can not find the Person. return null; }头说这么不对,专家建议方法尽量不返回null,让我设置一个常量代替null,这叫 Null Object模式,于是又改成下面这样:
public Person fetch(String name){ //can not find the Person return Person.EMPTY_PERSON; }据说这种模式有两个好处:
1。减少if的判断语句。
2。提高程序的健壮性,会少很多NullPointer错误。确实,NullPointer错误应该是所有的java程序员遇到的最多的一个错误,也是比较让人头痛的错误。那次在论坛上看见一个人叫做NullPointer,我看见都很头痛。
但是这种模式真有这么神奇,可以完全消除null么?
现在我们从cache里获取了一个Person对象,要用它,那需不需要判断一下它是不是EMPTY_PERSON呢?如果需要,它和null有什么区
别?不就相当于重新定义了一个类型只能为Person的null么。如果使用者忘记检查了,直接当Person用,会有什么结果?比方调用
person.getName(),返回什么?null?这不还是会有NullPointer么,那返回空字符串?但要是更复杂的对象呢?比方要获取
Person的父亲,person.getParent(),返回什么?还是返回EMPTY_PERSON?那要是程序里要是想遍历一下person的族
谱,不就进入死循环了么。于是我又搜索了一下相关文章,发现Null Object 模式用在下面两个场景里确实有作用:
1。一种是返回集合的时候。如果返回集合时返回null,我们就必须多做一步判断:List persons = personCache.fetchAll(); if(persons!=null){ for(Person p:persons){ p.doSometing(); } }但如果返回的是一个空集合,我们就不需要判断是否为null了。
2。另一个场景是在策略模式(Strategy Pattern)或者状态模式(
State Pattern)中。这两种模式下,都是要根据一定的策略或者状态进行不同的操作,这种情况下设置一个默认的do nothing的Null Object很有用。
我们还是用Person的例子。比方每个Person都有个绝技,我们叫KillSkill。public interface KillSkill{ public void kill(Person p); } //降龙十八掌 public XiangLong implements KillSkill{ public void kill(Person p){ // 丐帮帮主之绝学,阳刚无匹,血减50。 p.blood = p.blood - 50; } } //独孤九剑 public DuGu implements KillSkill{ public void kill(Person p){ //剑魔独孤求败的绝学,风清扬传令狐冲 ,血减30。 p.blood = p.blood - 30; } } //Null Object public NullSkill implements KillSkill{ public void kill(Person p){ //do nothing } } public class Person { public int blood; public KillSkill killSkill; public Person(int blood,KillSkill killSkill){ this.blood = blood; this.killSkill = killSkill; } } public class PersonCache { public static Person[] callHeros() { //萧峰出场 Person qiaofeng = new Person(100, new XiangLong()); //令狐冲出场 Person linghuchong = new Person(100, new DuGu()); //该我出场了,我这样的平凡人没啥特殊的必杀技,就是伪装个侠客,混饭吃。 Person me = new Person(100, null); return new Person[]{qiaofeng, linghuchong, me}; } } Person boss = PersonCache.callBoss(); //现在有人遇到危难了,boss出场了,要雇佣几个侠客给自己报仇。 Person heros = PersonCache.callHeros(); //英雄们轮番上阵 for(Person p:heros){ p.killSkill.kill(boss); } //结果出错了。这里面有个假侠客,me,killSkill是null.漏馅了,看来这行混不下去了。有没有别的办法?Null Object模式。 Person me = new Person(100,new NullSkill()); //我学了一招do nothing的招数,这下没有NullPointer错误了,不容易被识破了。现在明白Null Object的使用领域了吧?
推荐一篇文章: The Null Design Pattern
这篇文章里有句话说的好,Null Object就相当于数学上的0,它本身代表nothing,起个占位的作用,对任何操作都没有影响(当然,个别例外是可以容忍的,比方0不能做除数)。0加10000次还是0。Null Object只有在这种情况下使用才是合理的。简单的一个判断方法就是你是否能把NullObject当一般对象使用并且不影响程序的逻辑和结果。如果回答是,则使用NullObject,如果回答否,则说明这个场景不适合Null Object模式。像我开始提到的那种场景就不适合使用Null Object 模式。
最后在探讨点题外内容。如果没法用Null Object,那就只能返回null了?使用者要是忘记检查是否为null就使用,不就会有令人头痛的NullPointer错误了么?还有一个办法就是抛出强制检查的异常,逼迫使用者拦截异常进行处理。不过这种方式也有很多争议,Hibernate的接口就引起了这样的争议。想象如果从Map里获取对像的时候,如果不存在就抛出异常,那是个多痛苦的事情。曾经用过一个JSON库(好像就是官方那个),如果json里没有那个属性,它就抛出异常,导致我用的很痛苦。
另外还有一个问题就是java的方法签名设计没有体现出对返回结果的约束。比方获取map中不存在的对象会返回null,这样的信息只能从文档中得知,从签名上看不出来。同样,从签名设计也看不出来参数是否可以为null,或者是否有其他限制(比方必须是大于0的整数),只有通过看文档或者运行后得到非法参数的错误后才能知道。主要原因就是java没有内置实现 契约式设计(Design by Contract)。当然,虽然java语言中没有内置这种功能,但还是有其他实现途径,Contract4J,就是用java 5的annotation来实现契约式设计的。
具体可参看下面这篇文章:AOP@Work: 用 Contract4J 进行组件设计好了,要回家了。以后要好好修炼功夫,再不能在自己的必杀技里do nothing了,还是要靠真本事吃饭。

-
在PC上体验google android 操作系统
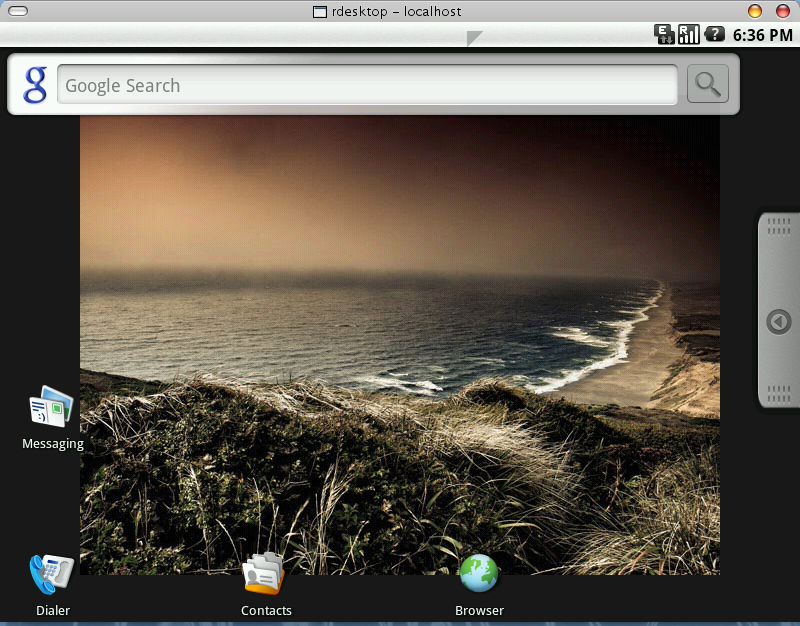
Android的桌面
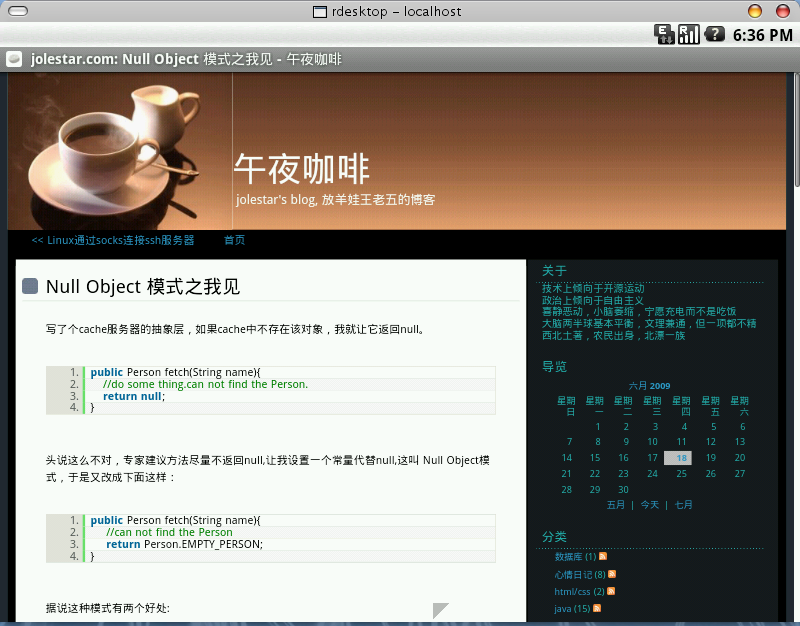
用Android访问本站的效果。竟然连javascript效果都支持,和pc上的浏览器基本没有差距。
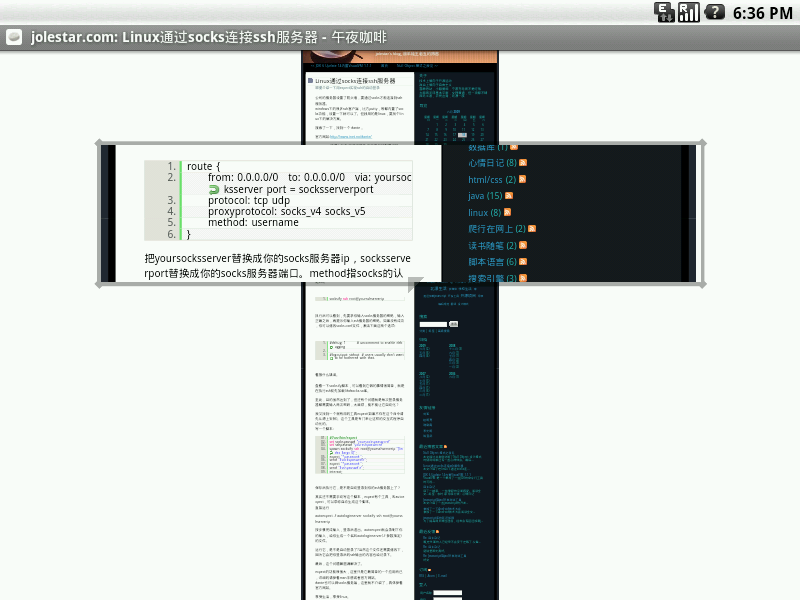
Android访问网页的放大镜效果。
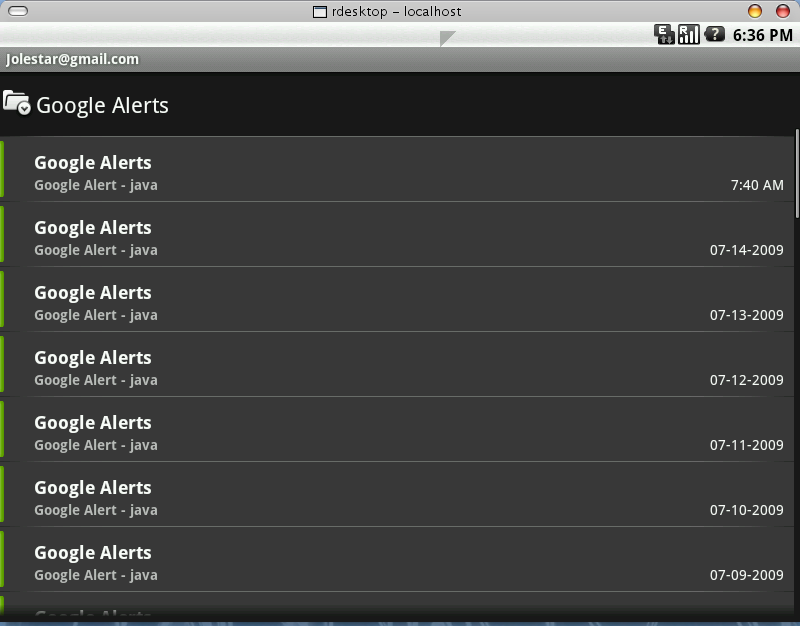
用Android接受邮件。
用Android阅读邮件。
是不是心动了?也想体验一下?
http://code.google.com/p/live-android/
下载livecd iso文件,然后刻录成光盘,用它启动电脑就可以啦。
如果不方便刻录的话可以用虚拟机虚拟,我就是这样做的。
-
回乡杂记
回了一趟家。
家乡依然如故。只是回家的路越坏了,到处是坑,一路颠簸。一眼望去,还是荒山野岭,零星几点野草。听见我们来了,父亲和阿姨到门上接我们。父亲的气色明显比以前好了。父亲本来就不善于交际,每天除了侍弄他那几亩庄稼,也没别的嗜好,不抽烟不喝酒不打麻将。打自母亲去世之后,屋里连个说话的人都没了,几年下来,父亲越发沉默寡言了。以前每次回家,家里到处都盖着厚厚一层灰尘,仿佛多年无人居住。阿姨说她整整收拾了三天,屋里才收拾的像个样子。阿姨心劲很强,屋里破旧的东西都给拆换掉了,还计划着要把屋里的地面弄成瓷砖的,把厨房给重盖一下。以前在电话里劝父亲别尽忙地里的活了,闲了就收拾收拾屋子,自己好好弄点吃的,父亲虽然口头上应着,但我能想象的到,父亲每天从地里忙回来,一见空荡荡的屋子,连个说话的人都没,弄饭吃的心劲都没了,更别说收拾下屋子改善生活啥的了。几年来,孤独与寂寞不断侵蚀着父亲,父亲迅速老去。现在总算好了,父亲能有个伴了,我们在外面也能安心工作了。第二天去母亲的坟上。母亲的坟在村南的山脚下。路被邻村的人开垦弄
没了,车过不去,我和弟弟就走了去。一个多小时的山路,其实实际距离不很远,但山头的样子都差不多,比较难找。没有墓碑,更没什么标志性的东西,连那一掊
黄土,也掩映在大山的土色里,不到近处分辨不出来。
故乡扫墓的习俗是烧纸钱,没有印好的纸钱,我们就带了几张黄纸在坟前点了。虽然烧纸钱这样的习俗对我这样顽固的无神论者来说有些荒诞,但纪念逝者总要有个仪式。逝者已逝,纪念活动也仅仅是慰藉一下生者的心灵,又何必执着于用哪种仪式。我和弟弟在母亲坟前坐了一会。几年了,我现在才算真真把这掊黄土和母亲联系起来。记得安葬母亲的时候,我看见这掊黄土堆了起来,但我老觉得母亲不会在这掊黄土下,母亲应该在家里的炕头坐着等我回去。每次回家远远看到院门,总觉得母亲会从门里出来接我们。我曾经说过人只有经历了亲人的逝去之后才能成熟起来,但其实那时候我还没成熟起来,因为我还老躲在自己的幻想里,逃避压力与责任。但我想我现在成熟起来了,也能承担起自己的责任了。
和家里人聊天的时候,得知我一个表叔,还有他两个儿子,一家三口去广州打工,全被骗到传销里出不来,传销那边向家里要钱。这个传销还是用暴力限制人身自由的那种,也不卖啥东西,就是明目张胆的绑架勒索。这样的事情已经听了许多了。好多同学还有亲戚出去打工都有过黑煤窑黑金矿黑砖厂,传销,等被骗或者强制劳动的经历。以前以为就我们那山村落后,出去的人太老实所以常被骗。结果出来才知道,这种事情太普遍了。管中窥豹,按照这个比例,中国现在应该有一个及其庞大的人口奴役市场。并且这种事情除了去年网上报道出来的那几个黑砖窑事件,别的都处于没人管的状态。两边的公安局互相扯皮,哪边都不管。更有甚着,公安局直接和这样的团伙勾结赚钱,把钱直接交给公安局,公安局批个条子,就能去传销团伙里把人领出来。前些年孙志刚案发生之前,政府收容遣送制度下,官匪结合,奴役外出打工人员的案例更是比比皆是。我们这代农村青年,已经不像父辈那样能安于那几亩庄稼,但寻找新的出路确实不容易。要么读书,跳出农门,但就业,成家的压力依然不小。还有就是外出进城打工。干最累的活,挣最少的钱,还常常被拖欠,在城市里看不到希望,更无法立足,唯一的希望就是攒点钱回老家去,还不小心就被骗被奴役。但在外面漂了几年的人,心已经野了,回到偏僻的山村,很难在安心下来。再就是干些法律边缘的事情,用高风险追求高收益。这样的人已经不安于踏踏实实赚钱过日子,尽谋划着怎么暴富。虽然这样的希望也是微乎其微,但还是有人前赴后继。主要是勤劳致富的案例不多,反倒为非作歹发家的案例却不少。榜样的力量在这里体现。我们这代从农村出来的青年,已经不适应农村的生存土壤,但又很难融入城市生活,城市用令人望而却步的房价和户口制度设置了一条很难跨越的墙。我们在两边徘徊,找不到归宿。
又了解了一下农村税费改革和医疗合作的情况。 税费改革还算比较彻底,现在每年每亩地还能收到几十元的补贴。医疗合作只有一个红本,父亲已经交了三年,原来每年10元,今年涨到20元。但具体怎么个报销法,哪些医疗费用能报销,也没个明确的说明。网上查了一下,说是各地的政策不同,有的只报销大病,有的只报销小病。标准,上线都不一样。还听说了有新政策给农村的老人发养老生活补贴。但说是要80岁以上的老人才行,还必须是贫困家庭。标准也就每年400-500块钱。就这样,村里人还要托关系走门路争取名额。农村的养老确实是一大问题了,已经听说好几起儿子媳妇抛弃或者虐待公婆事情。传统的父权制的崩溃,导致老人在家庭没有了经济地位,同时传统家族体制的消失,导致老人的权益无人主张。单凭一个“孝”已经很难承担起农村养老的重担了。因为传统的孝道的背后是父权制和家族制在支撑。计划生育已经搞了20多年了,而相应的农村养老制度却迟迟没有出台。回来的路上还看见墙上的宣传标语:独生子女户夫妻65岁后每年奖励650元。我的同龄同学朋友在农村的也大都步入婚姻生儿育女了,但等我们65岁的时候,谁知道那时候的650元能买个火柴还是萝卜?计划生育要靠养老制度来保障,而不是这种廉价的奖励。
庭院里当年种的一棵小梨树现在也枝叶繁茂,开花结果了。

记得当年种下它的时候,它和我的个头一般高,当时我还对它发愁,这么小棵树,啥时候能结梨子让我吃上呢,何况这地方干旱少雨,不知道能活下来不。父亲说现在每到秋天,满满一树的梨子都把它的枝桠压弯,要垂到地上了。父亲现在还每天要担一担水来给它浇了。这棵树让庭院里立刻充满绿意,让人暂时忘却屋外的荒山与沙漠。
生命有自己的运行规律,有些事情是抗拒不了的。以前对结婚成家这样的事情总觉得很遥远,但这趟回家后发现这个问题已经是家里阿姨阿婆们关心的主要问题了。在她们眼里,估计我就像这个当年的小梨树,现在也该到结果的时候了吧。以前对这些事情都比较排斥,现在算想明白了,很多事情顺其自然便好,勉强为之或者勉强不为都不好。
我的大脑对时间总有点麻木,所以经常恍惚间不知道是何年何月。在屋里坐在坐着,突然觉得自己还是个初中生,夏天躺在屋檐下朗诵庄子,看着天上的云彩,想象着山外那个世界。然后思绪忽然又飘了回来,掐指一算,竟然那已经是十年前的事情了,母亲去世都已经六年了。心里便一阵莫名的惶恐,仿佛我现在还处在记忆中,再恍惚一下,我就一下变成了一个老人坐在院子里回忆往事呢。人一长大对时间的流逝就无法保持童年的那种坦然态度了,想做的事太多,但做了的事情又太少,总是匆匆忙忙的,还总是觉得时间不够用。家里呆了两天就又匆匆回北京了。本来好像有好多话和家里人聊聊,但见了父亲又聊不了几句,都是不善言谈的人。回北京的时候坐在飞机上,突然又想起很多事没有聊,本来出门的时候要给父亲和阿姨好好说几句告别的话,但车来的匆忙,竟然也没顾上。
人或许就是这样,或者说人生或许就是这样,处处留着遗憾,即便你知道了也没法预防,总是顾此失彼,捉襟见肘。
-
Linux通过socks连接ssh服务器
公司的服务器设置了防火墙,要通过socks才能连接到ssh服务器。
windows下的很多ssh客户端,比方putty,等都内置了socks功能,设置一下就可以了。但我用的是linux,要找个linux下的解决方案。搜索了一下,找到一个 dante 。
官方网站:
opensuse的源上就有,安装很简单,下面是我的配置过程。
编辑/etc/socks.conf文件,在最后添加:
route { from: 0.0.0.0/0 to: 0.0.0.0/0 via: yoursocksserver port = socksserverport protocol: tcp udp proxyprotocol: socks_v4 socks_v5 method: username }把yoursocksserver替换成你的socks服务器ip,socksserverport替换成你的socks服务器端口。method指socks的认证方式。如果不需要认证就改成none。
如果是通过用户名验证的,则需要设置一个环境变量:
export SOCKS_USERNAME=yoursocksusername这个变量就是你的socks服务器的用户名。dante会通过这个环境变量来获取socks用户名。如果没有设置就用当前用户。
然后用socksify脚本来执行需要使用socks的程序,在这里是ssh。
socksify ssh root@yoursshserverip执行后可以看到,先要求你输入socks服务器的密码,输入正确之后,再提示你输入ssh服务器的密码。如果没有成功,你可以修改socks.conf文件,激活下面这两个选项:
#debug: 1 # uncomment to enable debugging #logoutput: stdout # users usually don't want to be bothered with that.看报什么错误。
查看一下socksify脚本,可以看到它做的事情很简单,就是在执行ssh前先加载libdsocks.so库。
至此,目的虽然达到了,但还有个问题就是每次登录服务器都需要输入两次密码,太麻烦,能不能让它自动化?
我又找到一个很有用的工具expect(如果不存在这个命令请先从源上安装)。这个工具是专门来让这样的交互式程序自动化的。
写一个脚本:#!/usr/bin/expect set sockspasswd "yoursockspassword" set sshpasswd "yoursshpassword" spawn socksify ssh root@yoursshserverip "[lindex $argv 0]"; expect "*password:"; send "$sockspasswdr"; expect "*password:"; send "$sshpasswdr"; interact;保存后执行它,是不是自动登录到你的ssh服务器上了?
其实还不需要手动写这个脚本,expect有个工具,叫autoexpect,可以帮你自动生成这个脚本。
直接运行autoexpect -f autologinserver socksify ssh root@yoursshserverip
按步骤完成输入,登录后退出。autoexpect就会录制下你的输入,给你生成一个名叫autologinserver(-f 参数指定)的文件。
运行它,是不是自动登录了?当然这个文件还需要修改下,因为它会把你登录后的ssh输出的内容也给记录下。
最后,这个问题算圆满解决了。
expect的功能很强大,这里只是它最简单的一个应用而已,详细的请参看man手册或者官方网站。
dante也可以做socks服务端,这里就不介绍了,具体参看官方网站。享受生活,享受linux。
-
JDK 6 Update 14内置VisualVM 1.1.1
VisualVM 是一个集成了一些JDK的命令行工具的可视化的工具,为您提供强大的分析能力。它捆绑了包括jstat , JConsole , jstack , jmap和jinfo,这些工具都您都可以在标准的JDK里找到。
VisualVM可以让您生成和分析堆数据,跟踪内存泄漏,监测垃圾收集器和内存CPU的性能,以及能够浏览和操作MBeans 。虽然VisualVM运行在JDK6上,但它可以监控创建自JDK1.4以上版本的应用程序 。
如果您的jkd没有更新到最新版本,您可以到以下地址下载:
下面这篇文章用Visualvm比较测试了三个java IDE( NetBeans 6.5.1 (JavaSE only version), Eclipse (for Java Developers) and IntelliJ IDEA (8.1.2) )的性能:
本文的VisualVM介绍也是翻译自该文。
VisualVM同时提供IDE插件,可以在IDE中直接使用VisualVM。
Sun还搞了个博客大赛,鼓励大家写博客介绍VisualVM,前三名都有奖励,最高奖励价值500美元,不过要求博客必须是英文写的。
如何启用tomcat的JMX,对远程tomcat进行监控,最简单的方式就是在tomcat的启动脚本里加上:
CATALINA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=$my.jmx.port -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djava.rmi.server.hostname=$my.jmx.host"$my.jmx.port $my.jmx.host这两个变量请根据具体情况替换。
如果要设置权限,以及更详细的配置,请参看下面这几篇文章:
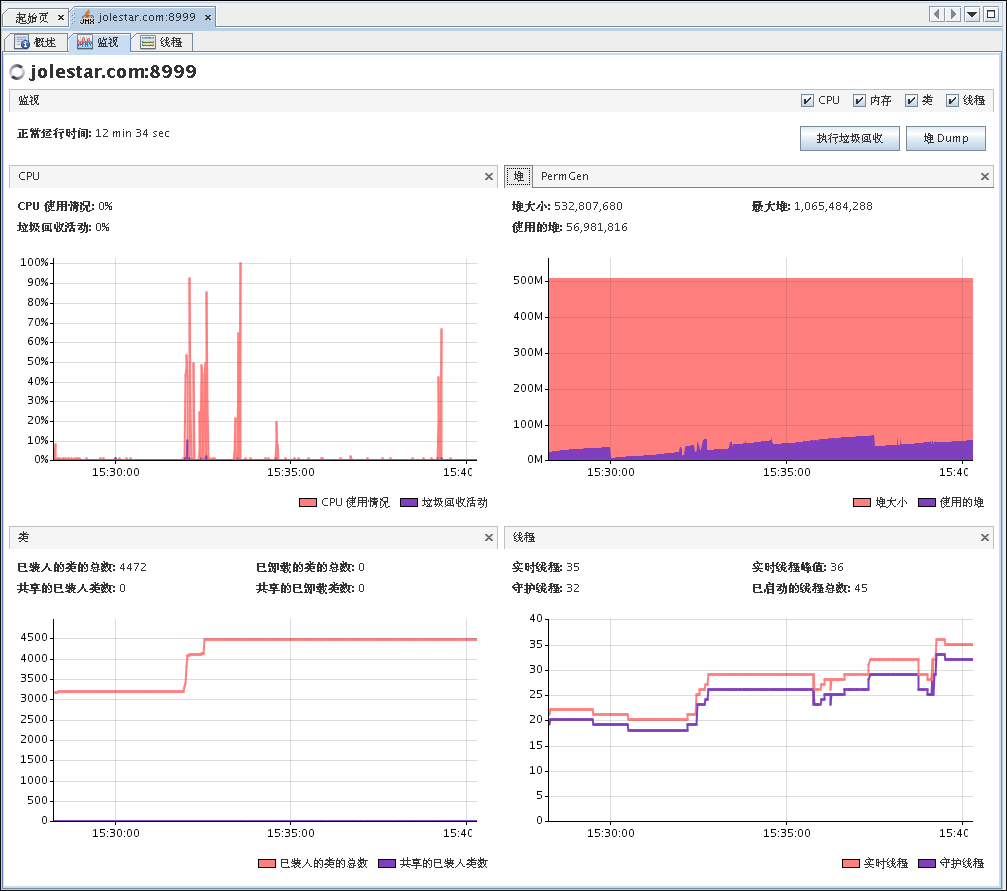
下图是本站的VisualVM监控截图:
subscribe via RSS